写在前面:python程序运行过程中要读取文件内容是读取所在工作目录文件夹下的文件,所以必须先打开该文件夹才能读取,否则会有类似这样的报错:FileNotFoundError: [Errno 2] No such file or directory: 'base64.txt'
在vscode上添加python运行环境理论上只要先下载某个版本的python再安装个python插件就行了
- pycharm运行python程序的时候是在相应的文件目录下运行的,而vscode是在相应的工程目录下运行的
- type() 显示类型信息
- python中变量没有类型,它储存的数据有类型
数据类型转换
1 | int(x) 将x转换为一个整数 |
ps:别的数据类型转字符串只要加上单引号或双引号,所以基本都能实现,但比如字符串转数字就要求字符串内容都是数字
字符串
定义
- 可以使用单、双、三引号
- 引号的嵌套可以使用\转义,也可以在单引号内写双引号或在双引号内写单引号
拼接
1、字符串和字符串直接使用+
2、字符串和变量
1 | 字符串格式化1 |
- 数字精度控制
使用辅助符号”m.n”来控制数据的宽度和精度 - m:控制宽度,宽度小于数字本身不生效,小数点和小数部分也算入宽度计算
- n:控制小数点精度,会进行小数的四舍五入
input
input():获取键盘输入的数据
ps:获取的数据都是字符串类型
if
1 | if 要判断的条件: |
for循环
1 | for 临时变量 in 待处理数据集: |
- 循环内的语句需要有空格缩进
- 严格来说,待处理数据集是序列类型
- 序列类型:字符串、列表、元组
1
2
3
4
5# for循环输出九九乘法表
for i in range(1, 10):
for j in range(1, i + 1):
print(f"{j}*{i}={j*i}\t", end='')
print()
range语句
1 | 语法一:range(num) |
while
1 | while 条件: |
- 条件需提供布尔类型的结果,true继续,false停止
- while循环可以嵌套
1
2
3
4
5
6
7
8
9# 输出九九乘法表
i=1
while i<=9:
j=1
while j<=i:
print(f"{j}*{i}={j*i}\t",end='')
j+=1
i+=1
print() # 换行 - continue:中断本次循环,直接进入下一次循环
- break:直接结束循环
ps:内层循环的continue和break不影响外层
函数
函数的定义
1 | def 函数名(传入参数): |
- 特殊字面量:None
不使用return语句即返回None - 使用场景:函数返回值、if判断、变量定义(不想给他赋值)
给python改了个阿里源,pip下载的速度快多了
变量在函数中的作用域
1 | num=100 |
testb中的num仍然是局部变量
加上global关键字
1 | num=100 |
python数据容器
1、什么是数据容器
一种可以存储多个元素的python数据类型
2、python有那些哪些数据类型
list列表、tuple元组、str字符串、set集合、dict字典
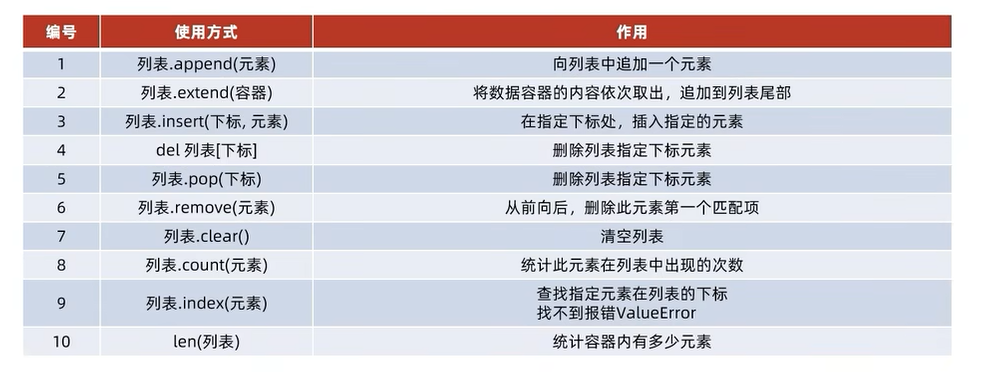
list(列表)
定义格式
1 | # 定义变量 |
- 元素可以是不同类型的数据,支持嵌套
Python encode方法
1 | gm:str.encode([encoding='utf-8'],[errors='strict']) |
bytes通过decode()转换为str(字符串)
str通过encode()转换为bytes(二进制)
1 | s='菜鸟教程' |
1 | 菜鸟教程 |
文件操作
f=open(“文件路径”,”r/w/a”,encoding=”UTF-8”) //f是文件对象名称
//w模式,输入的内容会覆盖原来文件的内容,a是在文件后追加内容,如果文件不存在就会创建文件
f.read(num):读取指定长度字节,不指定num就读取全部
f.readlines():读取文件的全部行,封装到列表中
f.readline():读取一行
for line in f: for循环文件行,一次循环得到一行数据,每一行返回成一个字符串,并且在末尾会有一个换行符
读取文件有个指针,所以如果前面读取到第一个数,下面的读取就会从第二个数开始读取
f.write(content):往文件中写入内容
f.close():文件关闭
with open(“文件路径”,”r/w/a”,encoding=”UTF-8”) as f:通过with open语法打开文件,可以自动关闭文件 //f是文件对象名称
1 | f = open("E:/test.txt", "r", encoding="UTF-8") |
先打开以只读的方式打开文件,计数器置零,用for循环,循环得到每一行的数据,用字符串的strip方法首尾去空,避免/n对匹配字符串的影响,然后用split方法将字符串以空格为分界,变成列表的形式,再用一个for循环将列表内的每个元素和”ttt”比较,如果相同,则计数器加1
异常
就是程序的bug,捕获异常是为了在程序出现异常之前做好准备,当出现异常的时候有处理的手段,这样就不会直接导致程序的崩溃
基本捕获语法
1 | try: |
如果try出现了异常就执行except的代码,也可以在没有出现异常的时候执行else代码,finally是最后必须要执行的代码,不管有没有异常。
捕获指定异常
1 | try: |
如果要捕获多个异常就可以用元组将上面的NameError进行替换,如果捕获全部异常就写except Exception as e:
- 异常的传递。。。
python的模块
定义
python模块是一个python文件,以.py结尾,模块能定义函数,类和变量,模块里也能包含可执行的代码
作用
python中有很多各种不同的模块,每一个模块都可以帮助我们快速实现一些功能,比如实现时间相关的功能就可以使用time模块,模块可以被认为是一个工具包。
eg:
1 | import time [as tt]//模块名,可以改成别名tt,后面就写tt.sleep |
按下ctrl然后鼠标左键点击模块名就可以查看.py文件的源代码
自定义python模块
新建一个python文件,命名并定义函数,模块名称就是文件名字,其他文件直接调用就行了
1 | def test(x, y): |
在if这个语句中的代码不会在导入模块的时候执行,所以既可以满足测试模块中函数的可行性又可以避免在导入模块的时候执行了代码
1 | __all__ = ['test'] //列表 |
如果在导入的时候如果是from my_module import *,则只能使用test
python包
python包是一个文件夹,可以存放很多模块,由各个模块和__init__.py组成,__init__.py用来标识这个文件夹是一个python包,导入包中的模块:import 包名.模块名,下面的使用就是包名.模块名.目标
- 第三方包(非python官方),安装后就可以使用,
pip install 包名就可以安装了,默认安装是连接国外的网站的,可以通过pip install -i 网址 包名指定网址安装